publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
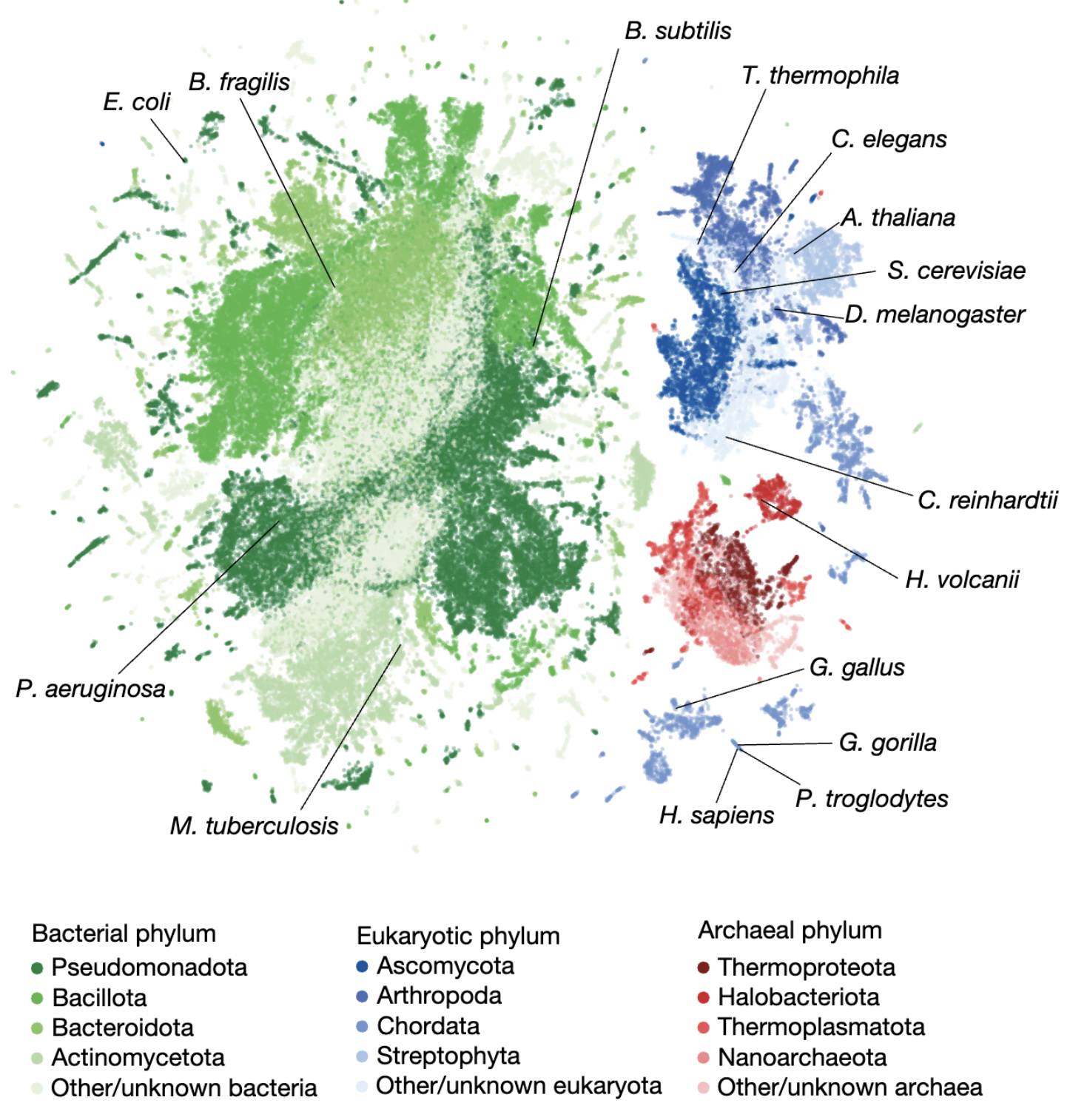
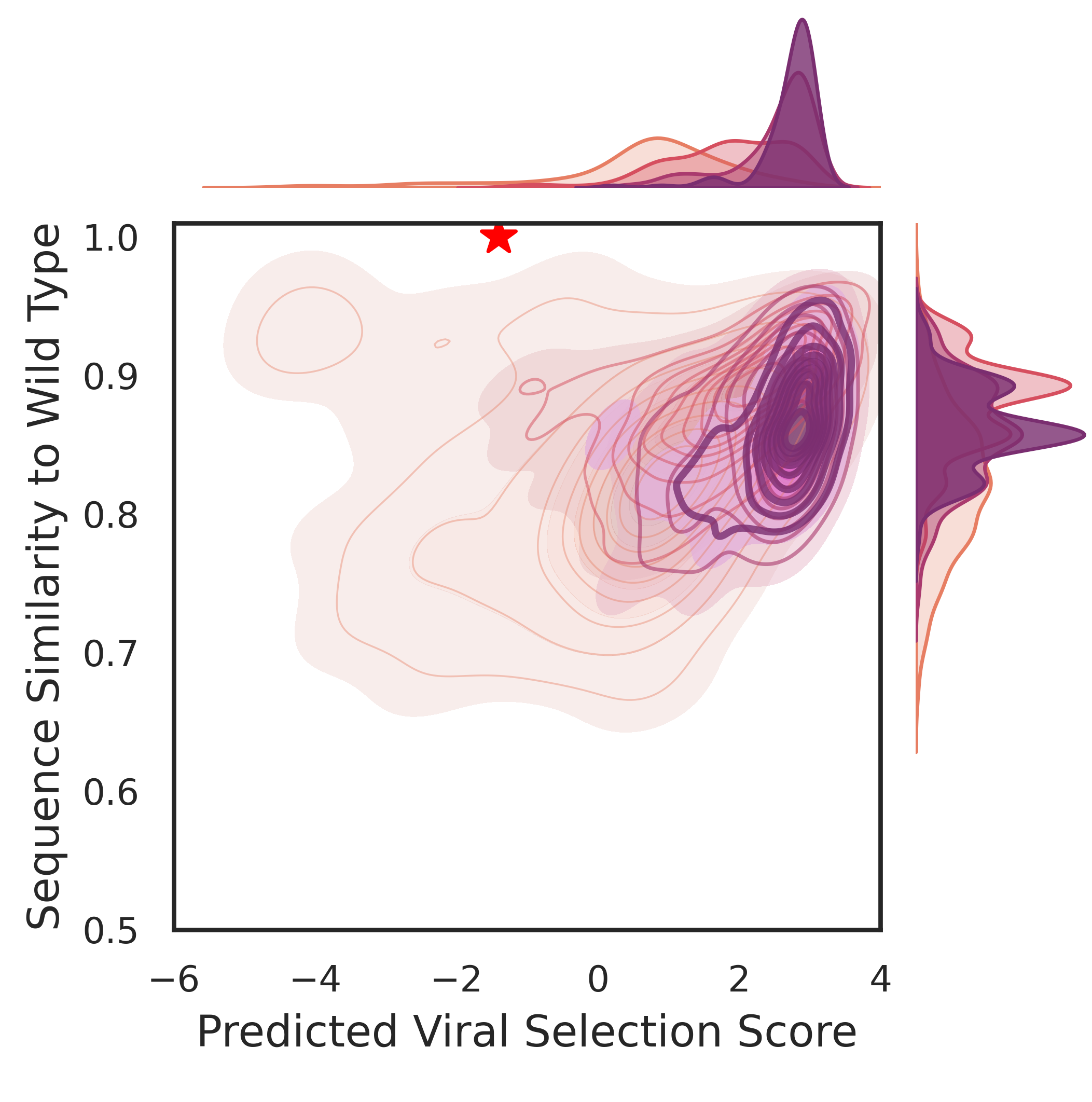
2025
2024
-
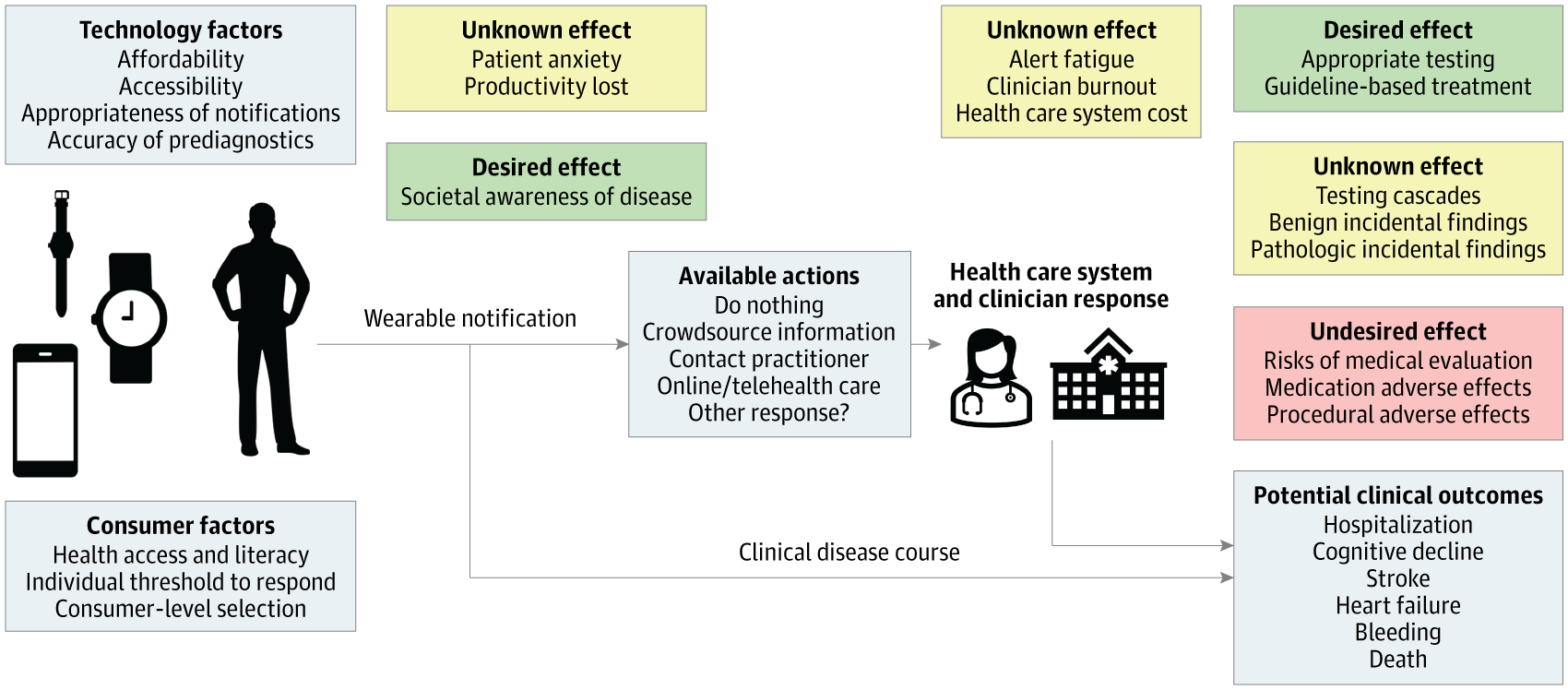
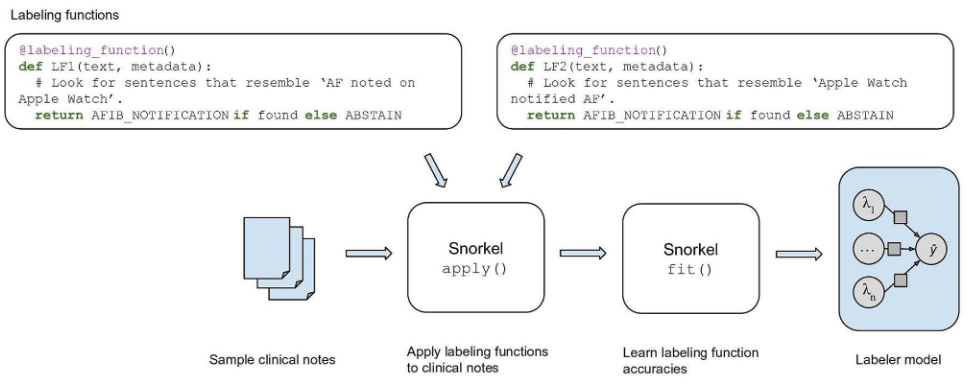 Scalable approach to consumer wearable postmarket surveillance: Development and validation studyApr 2024
Scalable approach to consumer wearable postmarket surveillance: Development and validation studyApr 2024 -
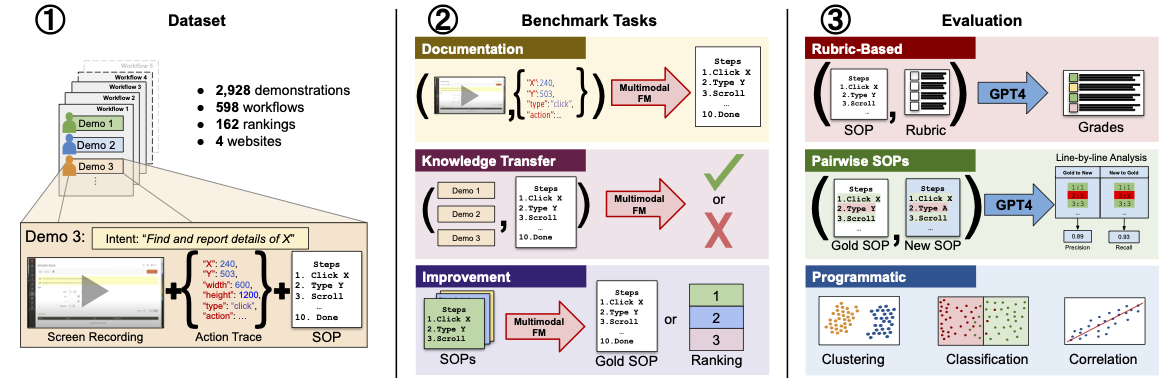 WONDERBREAD: A benchmark for evaluating multimodal foundation models on business process management tasksDec 2024
WONDERBREAD: A benchmark for evaluating multimodal foundation models on business process management tasksDec 2024
2023
-
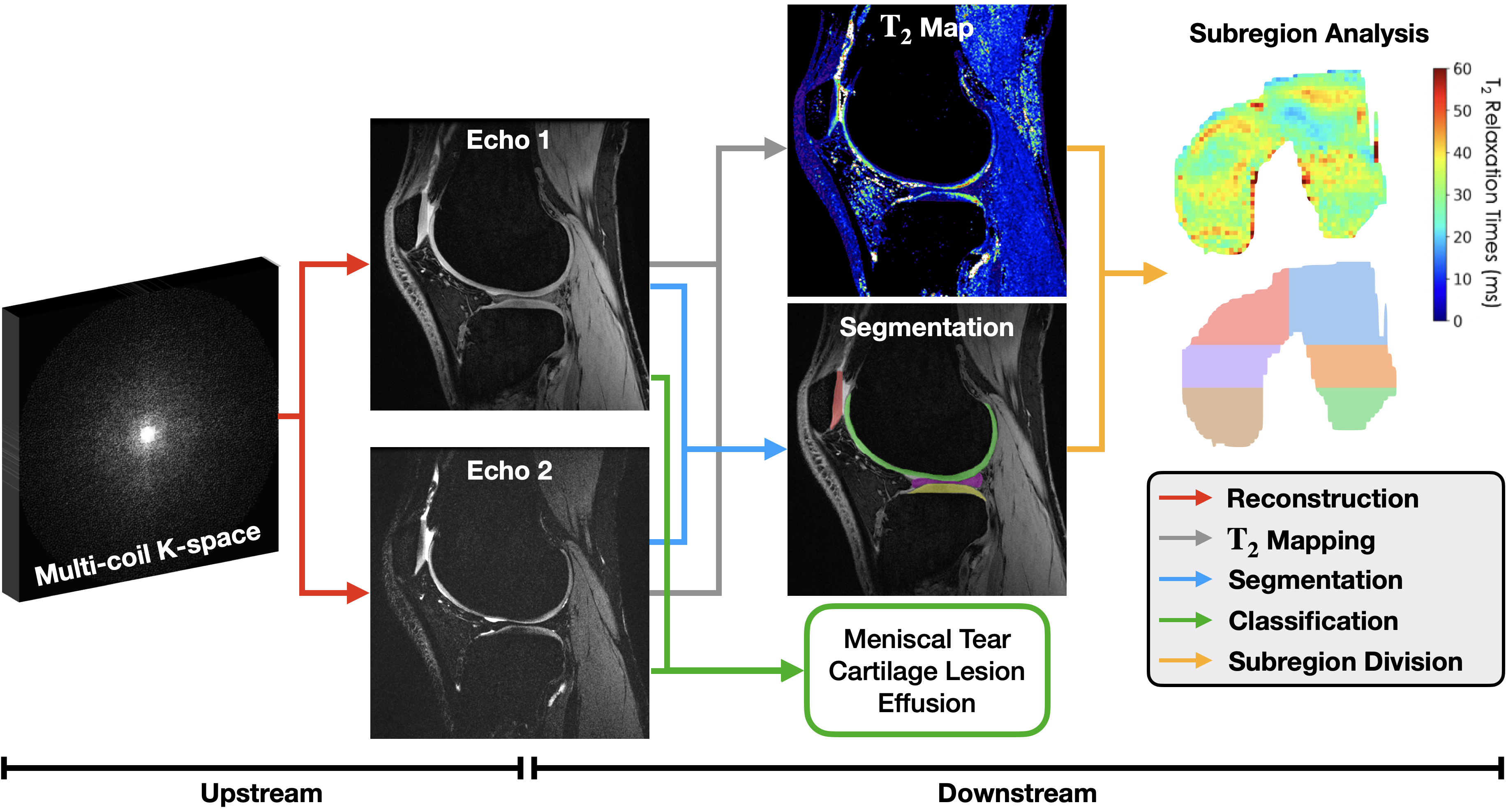 Assessing the impact of upstream reconstruction models on downstream image analysis: A workflow-centric evaluationNov 2023
Assessing the impact of upstream reconstruction models on downstream image analysis: A workflow-centric evaluationNov 2023
2021
-
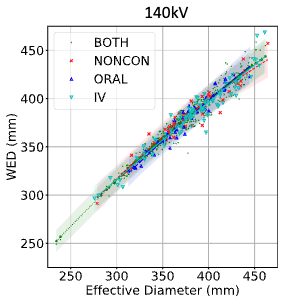
 A metric for quantification of iodine contrast enhancement (Q-ICE) in computed tomographyAug 2021
A metric for quantification of iodine contrast enhancement (Q-ICE) in computed tomographyAug 2021 -
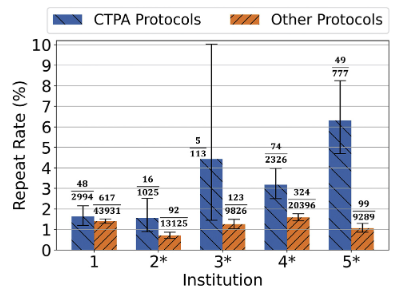 Applying a new CT quality metric in radiology: How CT pulmonary angiography repeat rates compare across institutionsJul 2021
Applying a new CT quality metric in radiology: How CT pulmonary angiography repeat rates compare across institutionsJul 2021 -
-
2020
-
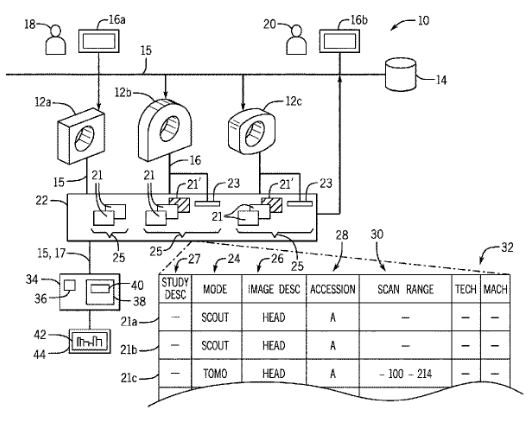
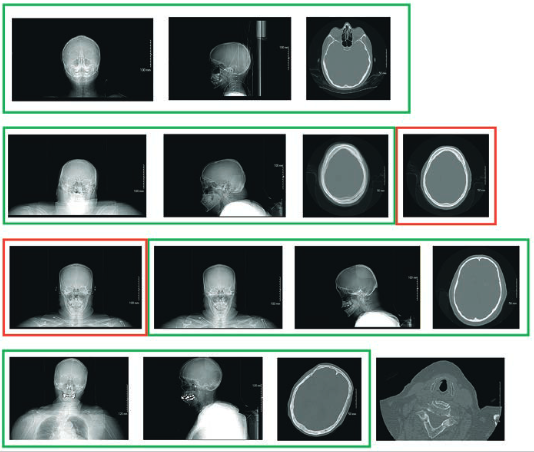 A multiinstitutional study on wasted CT scans for over 60,000 patientsNov 2020
A multiinstitutional study on wasted CT scans for over 60,000 patientsNov 2020